There is no place like home, and also: there is no place like production. Production is the only location where your code is really put to the test by your users. This insight has helped developers to accept that we have to go to production fast and often. But we also want to do so in a responsible way. Common tactics for safely going to production often are for example blue-green deployments and the use of feature flags.
While helping to limit the impact of mistakes, the downside of these two approaches is that they both run only one version of your code. Either by using a different binary or by using a different code path, the one or the other implementation is executed. But what if we could execute both the old and the new code in parallel and compare the results? In this post I will show you how to run two algorithms in parallel and compare the results, using a library called scientist.net, which is available on NuGet.
The use case
To experiment a bit met experimentation I have created a straight forward site for calculation the nth position in the Fibonacci sequence as you can see below.

I started out with the most simple implementation that seemed to meet the requirements of the implementation. In other words, the implementation behind this calculation is done using recursion, like shown below.
public class RecursiveFibonacciCalculator : IRecursiveFibonacciCalculator
{
public Task<int> CalculateAsync(int position)
{
return Task.FromResult(InnerCalculate(position));
}
private int InnerCalculate(int position)
{
if (position < 1)
{
return 0;
}
if (position == 1)
{
return 1;
}
return InnerCalculate(position - 1) + InnerCalculate(position - 2);
}
}
While this is a very clean and to-the-point implementation code wise, the performance is -to say the least- up for improvement. So I took a few more minutes and I came up with an implementation which I believe is also correct, but also much more performant, namely the following:
public class LinearFibonacciCalculator : ILinearFibonacciCalculator
{
public Task<int> CalculateAsync(int position)
{
var results = new int[position + 1];
results[0] = 0;
results[1] = 1;
for (var i = 2; i <= position; i++)
{
results[i] = results[i - 1] + results[i - 2];
}
return Task.FromResult(results[position]);
}
}
However, just swapping implementations and releasing didn’t feel good to me, so I thought: how about running an experiment on this?
The experiment
With the experiment that I am going to run, I want to achieve the following goals:
- On every user request, run both my recursive and my linear implementation.
- To the user I want to return the recursive implementation, which I know to be correct
- While doing this, I want to record:
- If the linear implementation yields the same results
- Any performance differences.
To do this, I installed the Scientist NuGet package and added the code shown below as my new implementation.
public async Task OnPost()
{
HasResult = true;
Position = FibonacciInput.Position;
Result = await Scientist.ScienceAsync<int>("fibonacci-implementation", experiment =>
{
experiment.Use(async () => await _recursiveFibonacciCalculator.CalculateAsync(Position));
experiment.Try(async () => await _linearFibonacciCalculator.CalculateAsync(Position));
experiment.AddContext("Position", Position);
});
}
This code calls into the Scientist functionality and sets up an experiment with the name fibonacci-implementation that should return an int. The configuration of the experiment is done using the calls to Use(..) and Try(..)
Use(..): The use method is called with a lambda that should execute the known, trusted implementation of the code that you are experimenting with.
Try(..): The try method is called with another lambda, but now the one with the new, not yet verified implementation of the algorithm.
Both the Use(..) and Try(..) method accept a sync-lambda as well, but I do use async/await here on purpose. The advantage of using an async-lambda is that both implementations will be executed in parallel, thus reducing the duration of the web server call. The final thing I do with the call to the AddContext(..) method is adding a named value to the experiment. I can use this context property-bag later on to interpret the results and to pin down scenarios in which the new implementation is lacking.
Processing the runs
While the code above takes care of running two implementations of the Fibonacci sequence in parallel, I am not working with the results yet – so let’s change that. Results can be redirected to an implementation of the IResultPublisher interface that ships with Scientist by assigning an instance to the static ResultPublisher property as I do in my StartUp class.
var resultsPublisher = new ExperimentResultPublisher(); Scientist.ResultPublisher = resultsPublisher;
In the ExperimentResultPublisher class, I have added the code below.
public class ExperimentResultPublisher : IResultPublisher, IExperimentResultsGetter
{
public LastResults LastResults { get; private set; }
public OverallResults OverallResults { get; } = new OverallResults();
public Task Publish<T, TClean>(Result<T, TClean> result)
{
if (result.ExperimentName == "fibonacci-implementation")
{
LastResults = new LastResults(! result.Mismatched, result.Control.Duration, result.Candidates.Single().Duration);
OverallResults.Accumulate(LastResults);
}
return Task.CompletedTask;
}
}
For all instances of the fibonacci-implementation experiment, I am saving the results of the last observation. Observation is the Scientist term for a single execution of the experiment. Once I have moved the results over to my own class LastResults, I am adding these last results to another class of my own OverallResults that calculated the minimum, maximum and average for each algorithm.
The LastResults and OverallResults properties are part of the IExperimentResultsGetter interface, which I later on inject in my Razor page.
Results
All of the above, combined with some HTML, will then gave me the following results after a number of experiments.
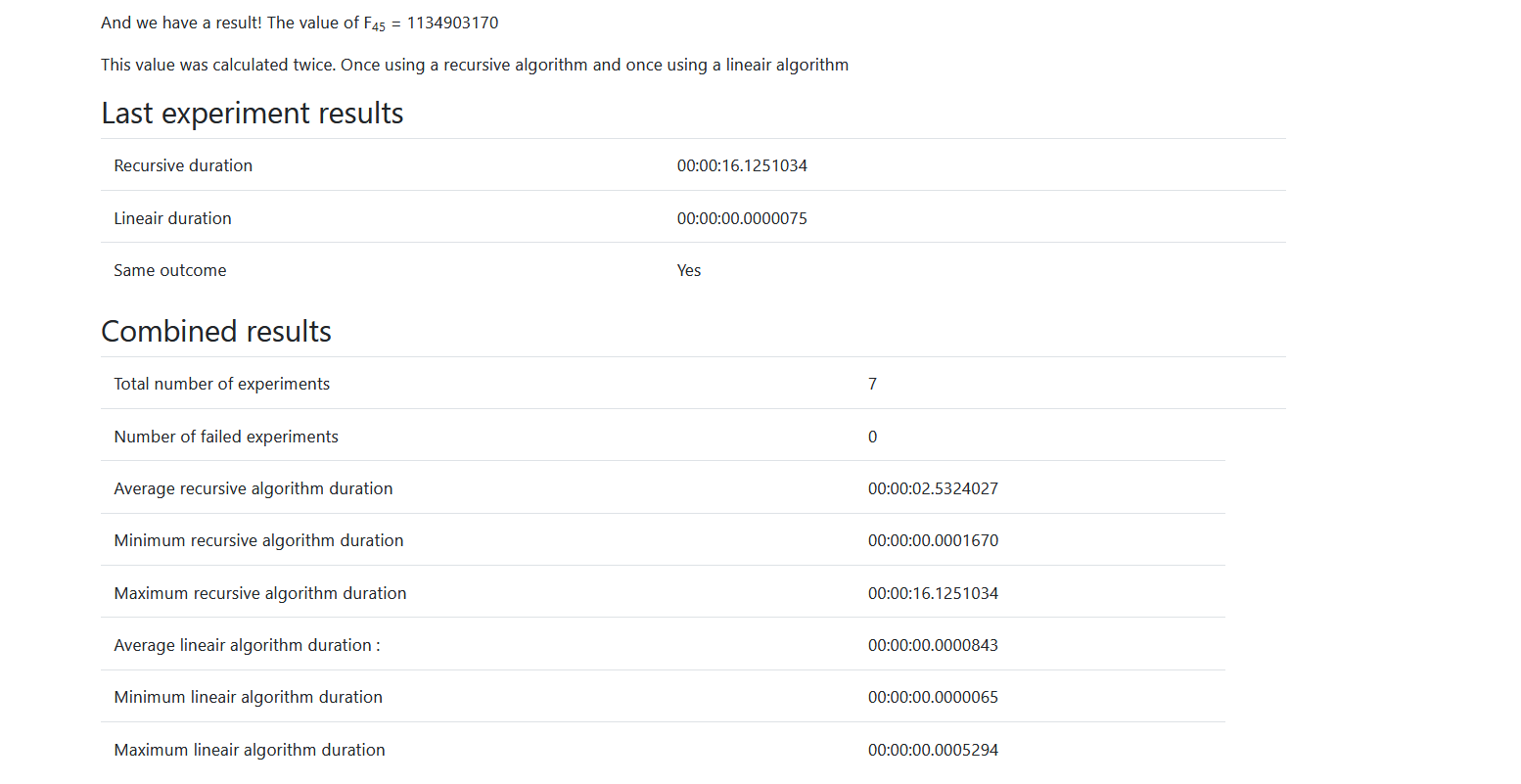
I hope you can see here how you can take this forward and extract more meaningful information from this type of experimentation. One thing that I would highly recommend is finding all observations where the existing and new implementation do not match and logging a critical error from your application.
Just imagine how you can have your users iterate and verify all your test cases, without them ever knowing.