If you are writing software applications and you take that seriously, it is very likely that you are also investing a constant percentage of your time in writing automated tests for your system. When you start out on this journey, you are -rightfully- focusing on unit tests. They are quick to write, quick to run and can be integrated with your build and deployment pipelines easily.
But when you come further down the road, you find that you need other types of tests as well: tests with a large scope like integration tests and systems. My definition of these two types of tests are these:
- Integration tests tests with a medium scope that run to verify if my assumptions and expectations regarding an external component are (still) true. The scope for this type of test is often one class (or a few classes) in my own codebase and an instance of the external system. These tests run much slower than unit tests, but also much faster than system tests. A typical execution takes around 1 second.
- System tests are tests with a large scope that run against a deployed version of my application. These tests run to verify if the system is correctly deployed and configured and if the most critical of flows are supported. These tests are the slowest of them all and execution can take anything between a few seconds (API test) up to a few minutes (UI test) I try to avoid writing them whenever I can.
In this post I want to share what I have come to view as good integration tests for verifying if my application code integrates with external systems correctly. I write these tests often as I find that they help me reason about how I want to integrate with external systems and help me identify and prevent all kinds of nitty-gritty issues that otherwise would have come to surface only after a deployment to test, during manual and/or system tests. I also use these tests for constantly verifying assumptions that I have about my (abstractions of) external systems. They help me detect changes in systems I integrate with, hopefully helping me to prevent integration issues.
Typical examples are:
- Code for reading from or writing to a messaging system like a topic or a queue
- Code for reading or writing data from an database
- Interactions with the file system or the current date and/or time
In the remainder I will take #2 as an example, as I believe it is an example we can all relate to.
Defining the abstraction
Integration points should be as thin as possible, to do this a right abstraction must be chosen: an interface that is as small as possible, yet captures all the dependencies your system has on the other system. Luckely, for many situations there are well-known abstractions. A prime example is the Repository-pattern for abstracting data stores. So in this example, let’s say I have an interface like this:
public interface IRecipesRepository
{
Task AddAsync(Recipe recipe);
Task<Recipe> GetByIdAsync(Guid id);
}
In my unit tests this is a simple and easy interface to mock away allowing me to effectively unit test my other classes, without the need to connect to the database.
Of course, it also forces me to write an implementation. Let’s assume something like this:
public class RecipesRepository : IRecipesRepository
{
private readonly IOptions<CosmosConfiguration> _cosmosConfiguration;
public RecipesRepository(IOptions<CosmosConfiguration> cosmosConfiguration)
{
_cosmosConfiguration = cosmosConfiguration;
}
public async Task AddAsync(Recipe recipe)
{
await GetContainer().UpsertItemAsync(recipe, new PartitionKey(recipe.Id.ToString()));
}
public async Task<Recipe> GetByIdAsync(Guid id)
{
var query= new QueryDefinition("SELECT * FROM c WHERE c.id = @id")
.WithParameter("@id", id.ToString());
var results = await GetContainer().GetItemQueryIterator<Recipe>(query).ToArrayAsync();
if (!results.Any())
{
throw new RecipeNotFoundException();
}
return results.Single();
}
private CosmosContainer GetContainer()
{
var client = new CosmosClient(
_cosmosConfiguration.Value.EndpointUrl,
_cosmosConfiguration.Value.AuthorizationKey);
return client.GetContainer(
_cosmosConfiguration.Value.RecipeDatabaseName,
_cosmosConfiguration.Value.RecipeContainerName);
}
}
And with the primary code in hand, let’s take a look at writing a first iteration of the test.
Writing a first test
A first test incarnation of a class for testing the implementation would be something like this:
[TestFixture]
public class RecipesRepositoryTest
{
[Test]
public async Task WhenStoringARecipe_ThenItCanBeReadBack()
{
// Arrange
var configuration = new CosmosConfiguration()
{
EndpointUrl = "https://integrationtestingexternalsystems.documents.azure.com:443/",
AuthorizationKey = "GjL...w==",
RecipeDatabaseName = "testDatabase",
RecipeContainerName = "testRecipes"
};
var repository = new RecipesRepository(Options.Create(configuration));
var expected = new Recipe("my Recipe");
// Act
await repository.AddAsync(expected);
var actual = await repository.GetByIdAsync(expected.id);
// Assert
Assert.AreEqual(expected.Name, actual.Name);
}
}
At first this looks like a proper test. It is nicely split into three parts: the arrange, act and assert. It tests one thing and it tests one thing only, so when it fails it is pretty clear what requirement is not being met and it is most likely pinpointing the cause pretty good. is also not to long, which means that it is very readable and understandable. However, it does have some downsides, which will become more clear when we add a second test.
Please note: we will get to the part where we strip out the secrets later on.
Writing a second test
After the first test, I have now added a second test. This makes that my test class now looks like this:
[TestFixture]
public class RecipesRepositoryTest
{
[Test]
public async Task WhenStoringARecipe_ThenItCanBeReadBack()
{
// Arrange
var configuration = new CosmosConfiguration()
{
EndpointUrl = "https://integrationtestingexternalsystems.documents.azure.com:443/",
AuthorizationKey = "GjL...w==",
RecipeDatabaseName = "testDatabase",
RecipeContainerName = "testRecipes"
};
var repository = new RecipesRepository(Options.Create(configuration));
var expected = new Recipe("my Recipe");
// Act
await repository.AddAsync(expected);
var actual = await repository.GetByIdAsync(expected.id);
// Assert
Assert.AreEqual(expected.Name, actual.Name);
}
[Test]
public void WhenAnRecipeIsRequested_AndItDoesNotExist_ThenItThrowsRecipeNotFoundException()
{
// Arrange
var configuration = new CosmosConfiguration()
{
EndpointUrl = "https://integrationtestingexternalsystems.documents.azure.com:443/",
AuthorizationKey = "GjL...w==",
RecipeDatabaseName = "testDatabase",
RecipeContainerName = "testRecipes"
};
var repository = new RecipesRepository(Options.Create(configuration));
// Act
AsyncTestDelegate act = async () => await repository.GetByIdAsync(Guid.NewGuid());
// Assert
Assert.ThrowsAsync<RecipeNotFoundException>(act);
}
}
With this second test in there, it becomes much more evident that it is time to make some changes. First of all, we can see that there is some repetition going on at the start of each test. Let’s use refactor the test class a little bit to use the SetUp attribute to centralize the repeated parts into a method that is executed again before every test. This yields a result like this:
[TestFixture]
public class RecipesRepositoryTest
{
private RecipesRepository repository;
[SetUp]
public void SetUp()
{
var configuration = new CosmosConfiguration()
{
EndpointUrl = "https://integrationtestingexternalsystems.documents.azure.com:443/",
AuthorizationKey = "Gj...w==",
RecipeDatabaseName = "testDatabase",
RecipeContainerName = "testRecipes"
};
repository = new RecipesRepository(Options.Create(configuration));
}
[Test]
public async Task WhenStoringARecipe_ThenItCanBeReadBack()
{
// Arrange
var expected = new Recipe("my Recipe");
// Act
await repository.AddAsync(expected);
var actual = await repository.GetByIdAsync(expected.id);
// Assert
Assert.AreEqual(expected.Name, actual.Name);
}
[Test]
public void WhenAnRecipeIsRequested_AndItDoesNotExist_ThenItThrowsRecipeNotFoundException()
{
// Act
AsyncTestDelegate act = async () => await repository.GetByIdAsync(Guid.NewGuid());
//Assert
Assert.ThrowsAsync<RecipeNotFoundException>(act);
}
}
However, the test is still not perfect. The main problem with this test is that it executes over and over again against the same test database and test container. This means that these will grow and grow over time, which is not good. For two reasons:
- It makes any failure hard to troubleshoot. If this test fails the 10.000th time it executes, there will be 10.000 records to go through to see what’s happening. It will be hard to say what the reason for the failure is: is the record is not stored at all? is the name field not correctly saved? is the name field not correctly deserialized? is the whole thing not read while it is in the database? or any other of many possible scenario’s. A failed test is so much easier to troubleshoot if there are only the records I need for this test, and no more.
- If I reuse this container for an ever growing number of tests, at some point there will be tests that leave recipes that influence other tests. Test runs will have side-effects on the test-data available to other tests. Which means that tests will start to interfere with each other, which is really, really bad. If such a thing starts happening, it will most likely result in a few random tests starting to fail in every test run. Often different tests in every run as well. Hard to troubleshoot and very hard to fix. (By the way: if you are ever tempted to fix such a problem by imposing an order among the tests: don’t. Instead make all tests independent of each other and free of side-effects again.)
The best way to prevent all these problems is simply to create an isolated Cosmos DB container for each test. One way for effectively managing that, is using a test context. A test context is a concept that we introduce to capture everything that surrounds the test, but is strictly speaking not a part of the test itself.
Extracting a test context class
Test contexts are classes that I write for supporting my tests with capabilities that are needed, but not part of the test self. In this case, we will need a class that can be used to do the following:
- Create a new CosmosDB container for every test
- Remove that container after the test completes
- Provide relevant information or configuration to my tests, when needed
A test context class for testing a repository that runs against a cosmos container, might look something like this:
public class CosmosDbRepositoryTestContext
{
private CosmosConfiguration _configuration;
private CosmosContainer _container;
public async Task SetUpAsync()
{
_configuration = new CosmosConfiguration()
{
EndpointUrl = "https://integrationtestingexternalsystems.documents.azure.com:443/",
AuthorizationKey = "GjL...w==",
RecipeDatabaseName = "testDatabase",
RecipeContainerName = $"integrationtest-{Guid.NewGuid()}"
};
var cosmosclient = new CosmosClient(_configuration.EndpointUrl, _configuration.AuthorizationKey);
var database = cosmosclient.GetDatabase(_configuration.RecipeDatabaseName);
var containerResponse = await database.CreateContainerIfNotExistsAsync(
_configuration.RecipeContainerName, "/id");
_container = containerResponse.Container;
}
public async Task TearDownAsync()
{
await _container.DeleteContainerAsync();
}
public CosmosConfiguration GetCosmosConfiguration()
{
return _configuration;
}
}
Here we can see that, instead of reusing the same collection over and over, I am creating a new collection within the context. The context also provides capabilities for getting the reference to that container and the means for cleaning up. Now you might wonder, why a separate class? Why not execute this fairly limited amount of code from the test class itself? The reason is quite simple: reuse. If I want to implement more repository classes, they are also going to depend on an CosmosConfiguration for instantiation. That means that I can reuse this test context for all my repositories that work with CosmosDB.
Having this context, means that my test class itself can now focus on the actual test execution itself:
[TestFixture]
public class RecipesRepositoryTest
{
private CosmosDbRepositoryTestContext _cosmosDbRepositoryTestContext;
private RecipesRepository _repository;
[SetUp]
public async Task SetUp()
{
_cosmosDbRepositoryTestContext = new CosmosDbRepositoryTestContext();
await _cosmosDbRepositoryTestContext.SetUpAsync();
_repository = new RecipesRepository(
Options.Create(_cosmosDbRepositoryTestContext.GetCosmosConfiguration()));
}
[TearDown]
public async Task TearDown()
{
await _cosmosDbRepositoryTestContext.TearDownAsync();
}
[Test]
public async Task WhenStoringARecipe_ThenItCanBeReadBack()
{
// Arrange
var expected = new Recipe("my Recipe");
// Act
await _repository.AddAsync(expected);
var actual = await _repository.GetByIdAsync(expected.id);
// Assert
Assert.AreEqual(expected.Name, actual.Name);
}
[Test]
public void WhenAnRecipeIsRequested_AndItDoesNotExist_ThenItThrowsRecipeNotFoundException()
{
// Act
AsyncTestDelegate act = async () => await _repository.GetByIdAsync(Guid.NewGuid());
//Assert
Assert.ThrowsAsync<RecipeNotFoundException>(act);
}
}
Now that we have all the ceremony moved to the test context, let’s see if we can get rid of that nasty hardcoded CosmosConfiguration.
Extracting a settings file
NUnit, the testing framework I use here, supports the use of runsettings files. These files can be used for capturing all the settings that are used throughout the tests. To reference a setting from such a file, the following syntax can be used: TestContext.Parameters["settingName"]Here TestContext does not reffer to my own work, but to the test context that NUnit provides, including access to the settings. Inserting this into our own CosmosDbRepositoryTestContext class will yield the following:
public class CosmosDbRepositoryTestContext
{
private CosmosConfiguration _configuration;
private CosmosContainer _container;
public async Task SetUpAsync()
{
_configuration = new CosmosConfiguration()
{
EndpointUrl = TestContext.Parameters["EndpointUrl"],
AuthorizationKey = TestContext.Parameters["AuthorizationKey"],
RecipeDatabaseName = TestContext.Parameters["RecipeDatabaseName"],
RecipeContainerName = $"integrationtest-{Guid.NewGuid()}"
};
var cosmosclient = new CosmosClient(_configuration.EndpointUrl, _configuration.AuthorizationKey);
var database = cosmosclient.GetDatabase(_configuration.RecipeDatabaseName);
var containerResponse = await database.CreateContainerIfNotExistsAsync(
_configuration.RecipeContainerName, "/id");
_container = containerResponse.Container;
}
public async Task TearDownAsync()
{
await _container.DeleteContainerAsync();
}
public CosmosConfiguration GetCosmosConfiguration()
{
return _configuration;
}
}
And to provide values for the test, a runsettings file has to be created. I always create two of them, the first one goes in my solution and looks like this:
<?xml version="1.0" encoding="utf-8"?>
<RunSettings>
<TestRunParameters>
<Parameter name="EndpointUrl" value="#{EndpointUrl}#" />
<Parameter name="AuthorizationKey" value="#{AuthorizationKey}#" />
<Parameter name="RecipeDatabaseName" value="#{RecipeDatabaseName}#" />
</TestRunParameters>
</RunSettings>
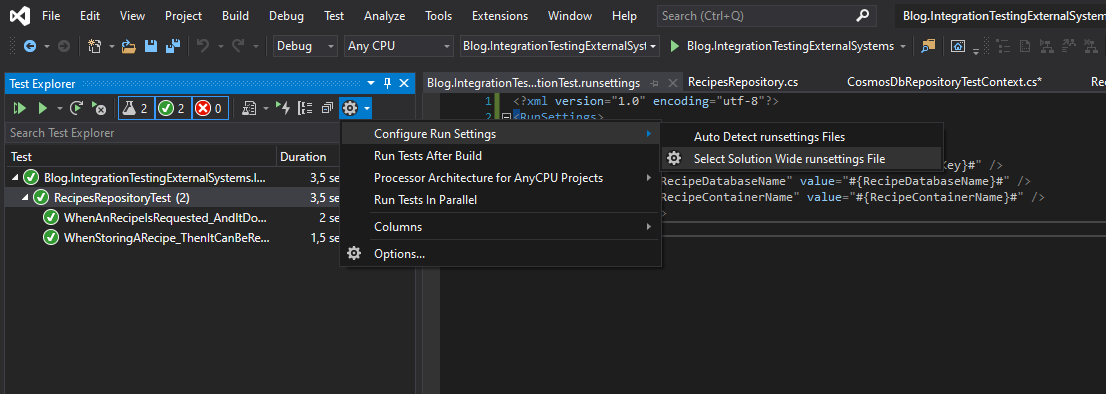
In this file I provide all the values that are needed when running the tests from a pipeline, excluding the secrets and any values that are dependent on the infrastructure creation. For these values I insert placeholders that I will later replace using a task in the pipeline. This way I ensure that my integration tests always use the infrastructure created earlier and that secrets can be stored securely and not in source control. Besides this file that is in source control, I will also make a similar file on my local computer in a secure location that contains the actual values for testing from my own, personal machine. To run the test using this file, I use the Test Explore and configure a runsettings file like this:
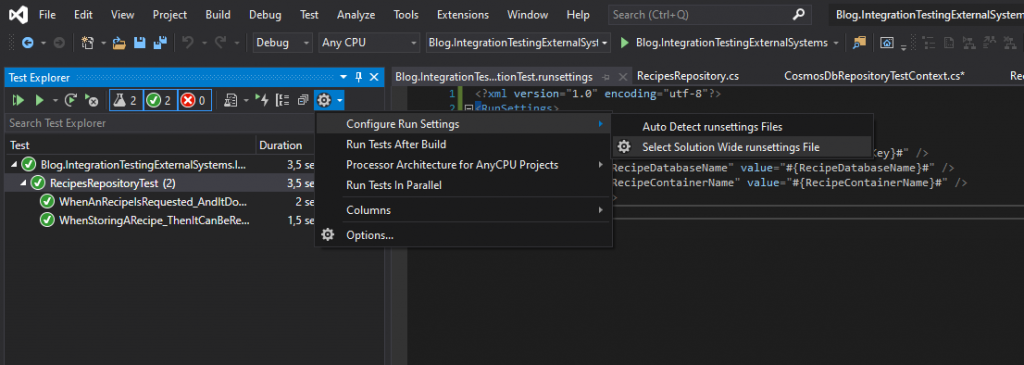
And with this final change we have removed settings and secrets and are still able to run our test while having prepared for running them from a pipeline as well.
Running integration tests from an pipeline
No blog regarding testing is complete without showing how to do it from a pipeline. In this case I want to show a pipeline consisting out of four tasks:
- A task that deploys an ARM template that creates an CosmosDB account and a database for testing in that account. The template also produces a number of outputs;
- A task that retrieves the outputs from task #1 and makes them available as pipeline variables;
- A task that read the runsettings file and replaces the tokens with the outputs retreived in task #2;
- Finally, a task is run that executes the integration test, passing in the correct runsettings file.
As all pipelines in Azure DevOps are YAML nowadays, the following shows how this can be done.
trigger:
- master
variables:
BuildConfiguration: 'Release'
ServiceConnectionName: 'CDforFunctionsX'
ResourceGroupName: 'Blog.IntegrationTestingExternalSystems'
ResourceGroupLocation: 'West Europe'
EnvironmentName: 'test'
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'ARM template deployment'
inputs:
azureSubscription: $(ServiceConnectionName)
resourceGroupName: $(ResourceGroupName)
location: $(ResourceGroupLocation)
csmFile: '$(System.DefaultWorkingDirectory)/Blog.IntegrationTestingExternalSystems.Deployment/armtemplate.json'
overrideParameters: '-environmentName "$(EnvironmentName)"'
deploymentMode: 'Incremental'
- task: keesschollaart.arm-outputs.arm-outputs.ARM Outputs@5
displayName: 'Fetch ARM Outputs'
inputs:
ConnectedServiceNameARM: $(ServiceConnectionName)
resourceGroupName: $(ResourceGroupName)
- task: qetza.replacetokens.replacetokens-task.replacetokens@3
displayName: 'Replace tokens in Blog.IntegrationTestingExternalSystems.IntegrationTest.runsettings'
inputs:
targetFiles: '$(System.DefaultWorkingDirectory)/Blog.IntegrationTestingExternalSystems.IntegrationTest/Blog.IntegrationTestingExternalSystems.IntegrationTest.runsettings'
- task: UseDotNet@2
inputs:
packageType: 'sdk'
version: '3.1.403'
- task: DotNetCoreCLI@2
displayName: 'Compile sources'
inputs:
command: 'build'
projects: '**/*.csproj'
arguments: '--configuration $(BuildConfiguration)'
- task: DotNetCoreCLI@2
displayName: 'Run integration tests'
inputs:
command: 'custom'
custom: 'vstest'
projects: '$(Build.SourcesDirectory)/Blog.IntegrationTestingExternalSystems.IntegrationTest\bin\$(BuildConfiguration)\netcoreapp3.1\Blog.IntegrationTestingExternalSystems.IntegrationTest.dll'
arguments: '--settings:$(Build.SourcesDirectory)/Blog.IntegrationTestingExternalSystems.IntegrationTest/Blog.IntegrationTestingExternalSystems.IntegrationTest.runsettings'
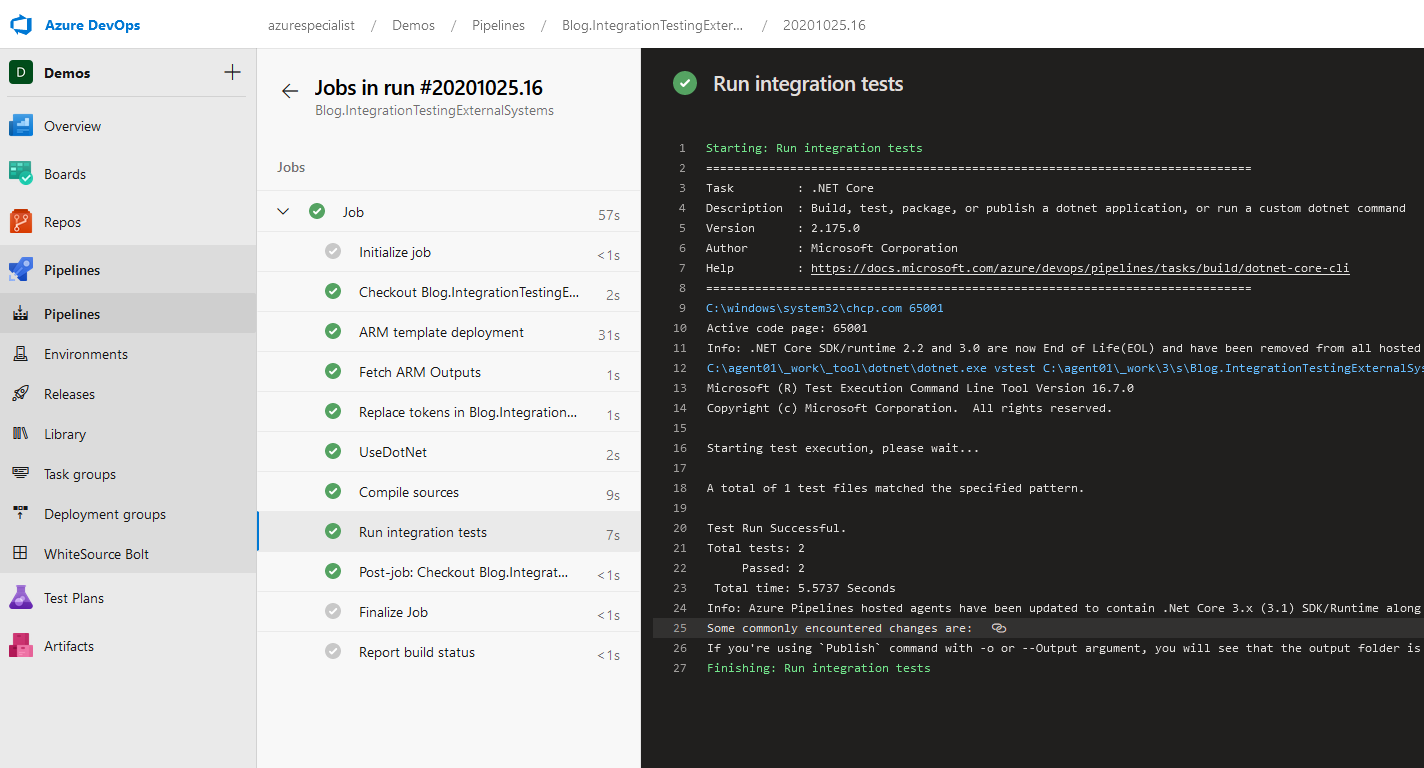
And to prove that this works, here a screenshot of the execution of this pipeline, publishing a successful test!
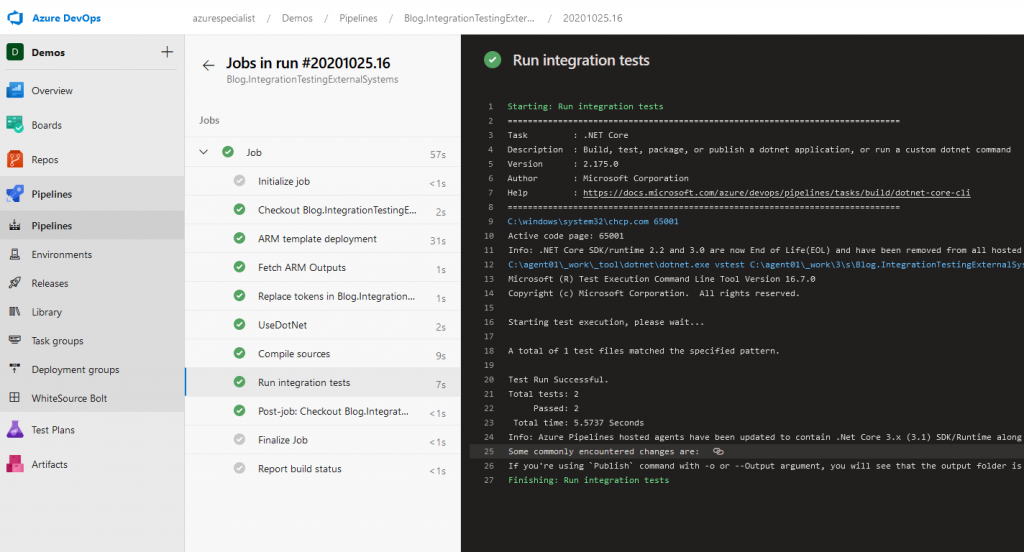
And that completes this example! I hope I have shown you how to create valuable, maintainable integration tests for verifying your integration exceptions regarding other systems and how to re verify those using tests that can run in your CI pipelines in a repeatable and reliable way.
The complete example can be found at https://github.com/henrybeen/Blog.IntegrationTestingExternalSystems/
Happy coding!