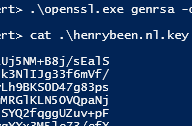
If you have been reading my previous two posts (part I & part II) on this subject, you might have noticed that neither solution I presented is perfect. Both solutions still suffer from storing secrets for local development in source control. Also combining configuration from multiple sources, can be be difficult. Luckily, in the newest versions of the .NET Framework and .NET Core there is a solution available that allows you to store your local development secrets outside of source control: user secrets.
User secrets are contained in a JSON file that is stored in your user profile and which contents can be applied to your runtime App Settings. Adding user secrets to you project is done by rightclicking on the project and selecting manage user secrets:
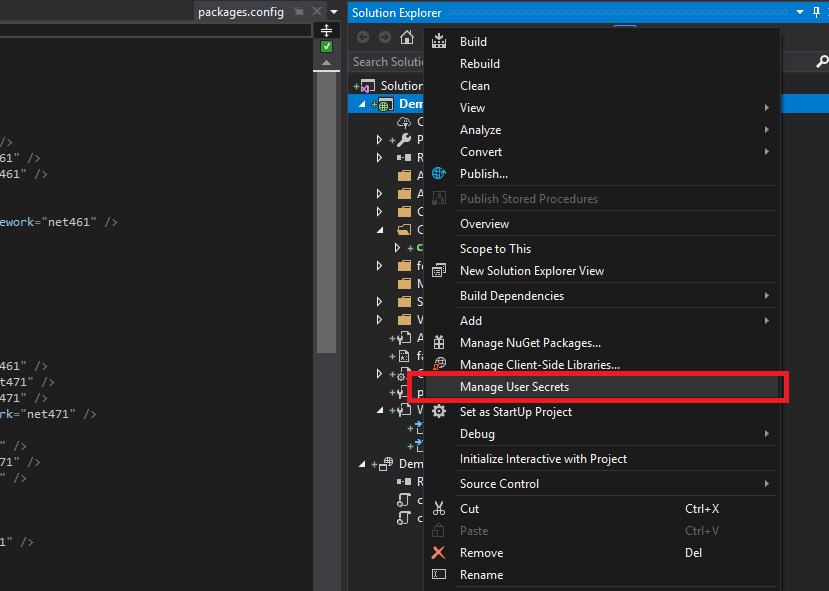
The first time you do this, an unique GUID is generated for the project which links this specific project to an unique file in your users folder. After this, the file is automatically opened up for editting. Here you can provide overrides for app settings:
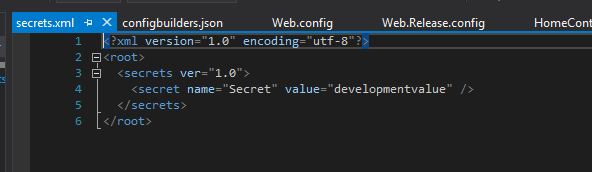
When starting the project now, these user secrets are loaded using config builders and available as AppSettings. So let’s take a closer look at these config builders.
Config builders
Config builders are new in .NET Framework 4.7.1 and .NET Core 2.0 and allow for pulling settings from one ore more other sources than just your app.config. Config builders support a number of different sources like user secrets, environment variables and Azure Key Vault (full list on MSDN). Even better: you can create your own config builder, to pull in configuration from your own configuration management system / keychain

The way config builders are used, differs between .NET Core and the Full Framework. In this example, I will be using the full framework. In the full framework config builders are added to your app.settings file. If you have added user secrets to your project, you will find an UserSecretsConfigBuilder in your Web.config already:
..
Important: If you add or edit this configuration by hand, do make sure that the configBuilders section is BEFORE the appSettings section.
Config builders and Azure KeyVault
Now let’s make this more realistic. When running locally, user secrets are fine. However, when running in Azure we want to use our Key Vault in combination with Manged Identity again. The full example is on GitHub and as in my previous posts, this example is based on first deploying an ARM template to set up the required infrastructure. With this in place, we can have our application read secrets from KeyVault on startup automatically.
Important: Your managed identity will need both list and get access to your Key vault. If not, you will get hard to debug errors.
As a first step, we have to install the config builder for Key Vault by adding the NuGET package Microsoft.Configuration.ConfigurationBuilders.Azure. After that, add an Web.config transformation for the Release configuration as follow:
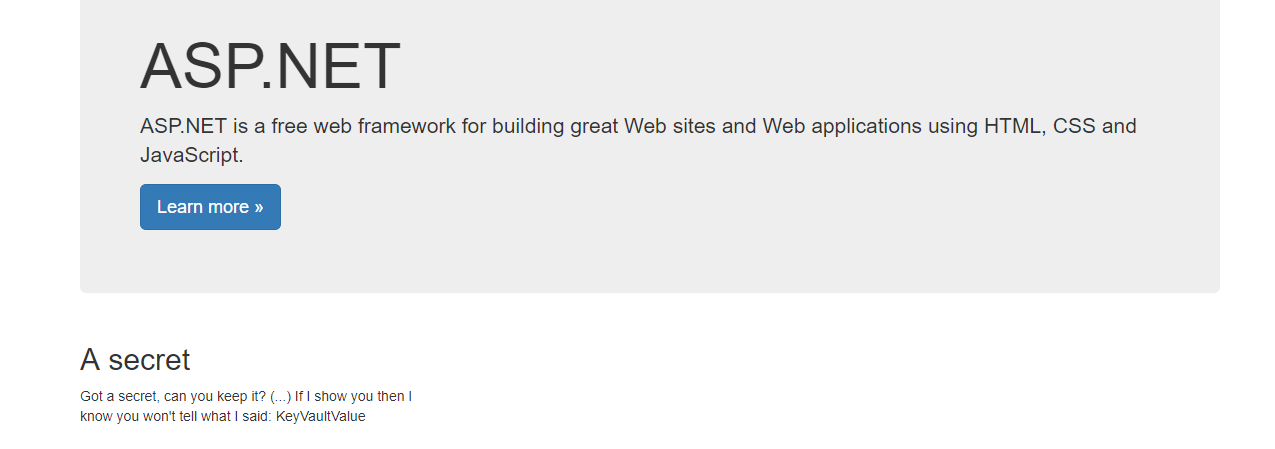
Now we just have to deploy and enjoy the result:
Happy coding!